電腦視覺(Computer Vision)一直是我非常著迷的領域,旨在模仿人類視覺系統,作為賦予機器人智能行為的助力,在1966年夏季,MIT AI LAB 成立並開始進行電腦視覺的研究,以下是其發展趨勢: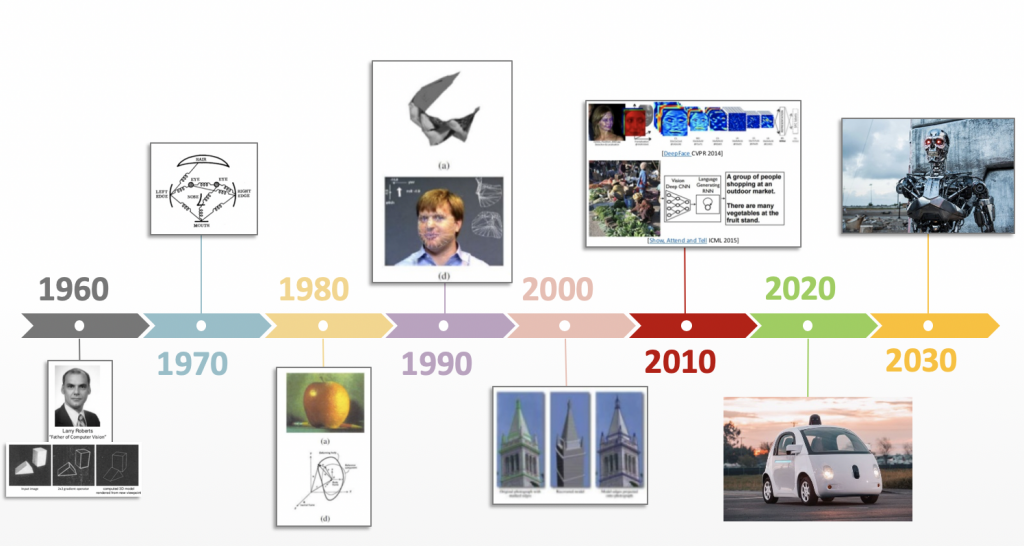
本文將介紹目前電腦視覺的應用和深度學習技術:
圖像分類(Image Classification)的問題定義:給定單一類別標籤的圖像,要求為一組未曾見過的測試圖像預測圖像類別並衡量預測的準確性。圖像分類涉及各種挑戰,包括雜訊、尺度變化、角度、光照、圖像變形、圖像遮蔽等等。深度學習使用數據驅動方法(data-driven approach )來解決這個問題。
最流行的架構是卷積神經網絡(CNN),CNN 的技術原理在 [魔法陣系列] Convolutional Neural Network(CNN)之術式解析 已提及,就不重複詳述了。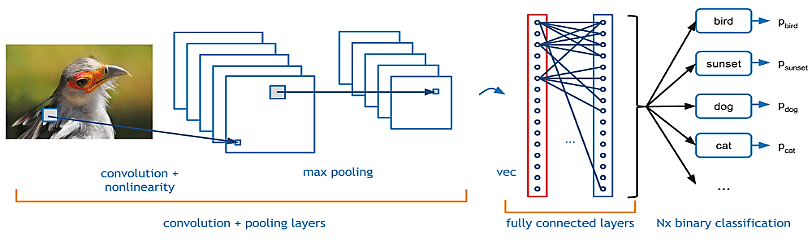
圖片來源:https://www.researchgate.net/figure/Deep-Convolutional-Neural-Network-CNN-for-classification-image-from-31_fig7_318277197
在圖像中要定義 Object ,通常涉及到 bounding box 跟該 Object 的標籤。Object Detection 跟上述 Image Classification 不同的是,它將分類跟定位(localization)應用在多個 objects 上,而非單一一個 Object。如下圖: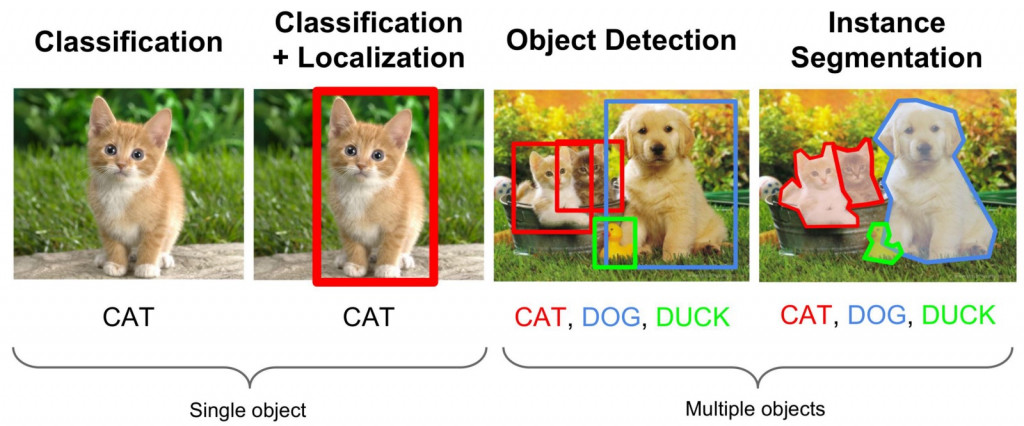
圖片來源:https://medium.com/comet-app/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
相關技術:
R-CNN(Region-based Convolutional Neural Network)
用 Selective Search 演算法掃描輸入的圖像以尋找可能的 Object,生成約兩千個 region proposals,然後在每個 region proposals 上使用 CNN,得到每個 CNN 的輸出後將其餵入 SVM 對 region 進行分類,並使用 linear regression 來收緊 Object 的 bounding box。
這個方法的缺點是,訓練緩慢,且需要大量的硬碟空間。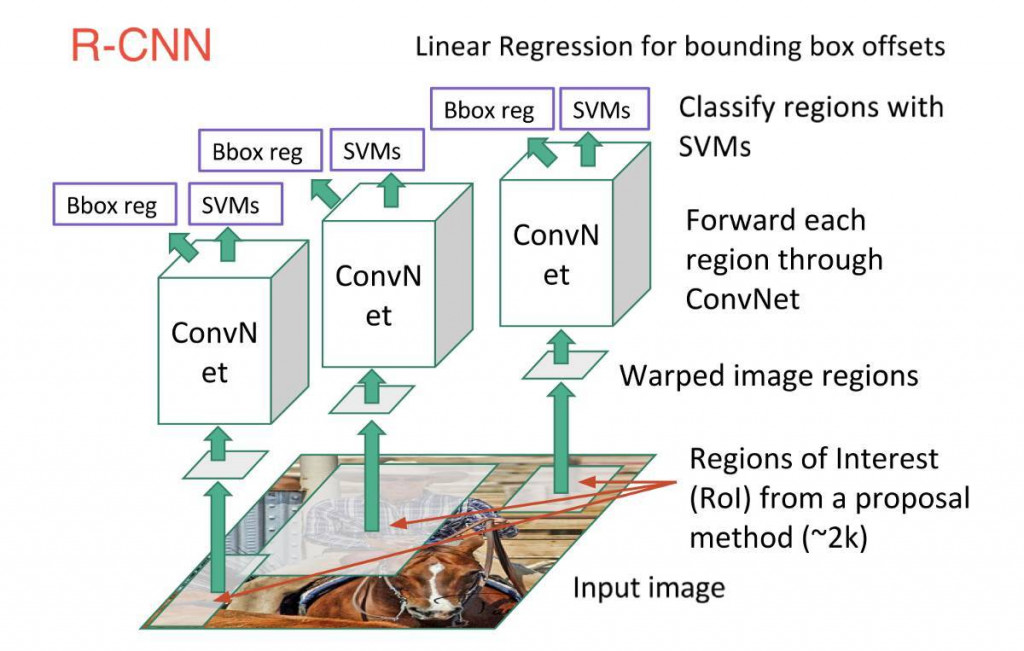
圖片來源:http://bangqu.com/952Y2o.html
Fast R-CNN
為了提升檢測速度,Fast R-CNN 的想法是只算一次 CNN 就好,所以僅在整個圖像上運行一個 CNN,再基於 feature map 創建了 region proposals,後續各自連接上 FC 網路,最後用 softmax 層替換 SVM。
Fast R-CNN 在速度方面表現得更好,因為它只為整個圖像訓練一個 CNN。 但是 Selective Search 演算法仍然需要花費大量時間來生成 region proposals。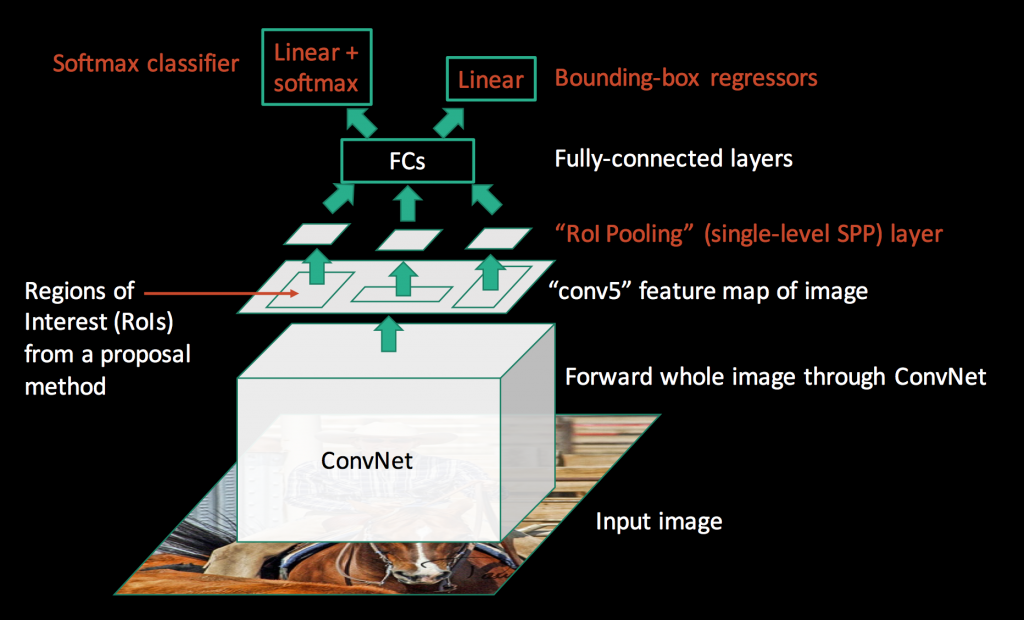
圖片來源:https://jhui.github.io/2017/03/15/Fast-R-CNN-and-Faster-R-CNN/
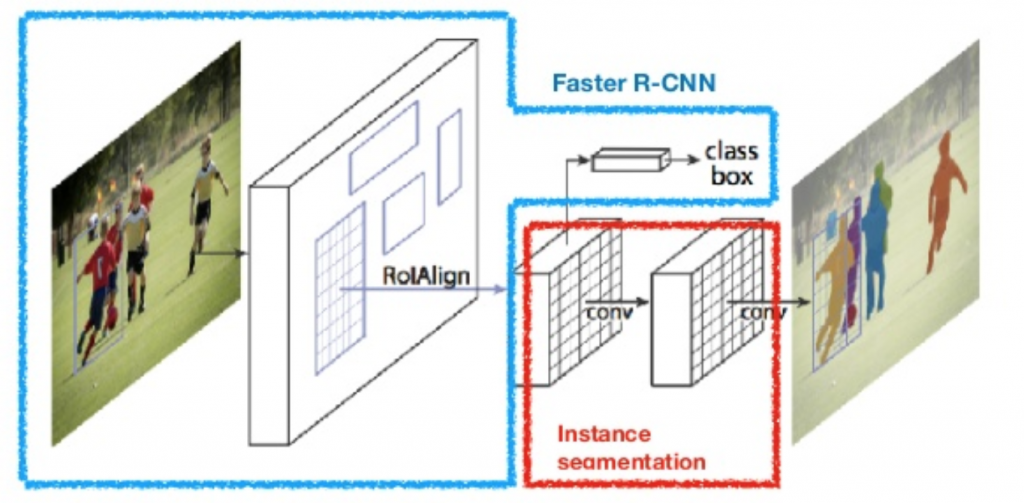
Faster R-CNN
Faster R-CNN 實現了更快的速度以及更高的準確率。它不使用 Selective Search 演算法,而是使用 Region Proposal Network (RPN) 來選出region proposals。RPN 本身也是一個卷積網絡,輸入(input)是之前 CNN 輸出的 feature map,輸出(output)是一個 bounding box 以及該 bounding box 包含一個物體的機率。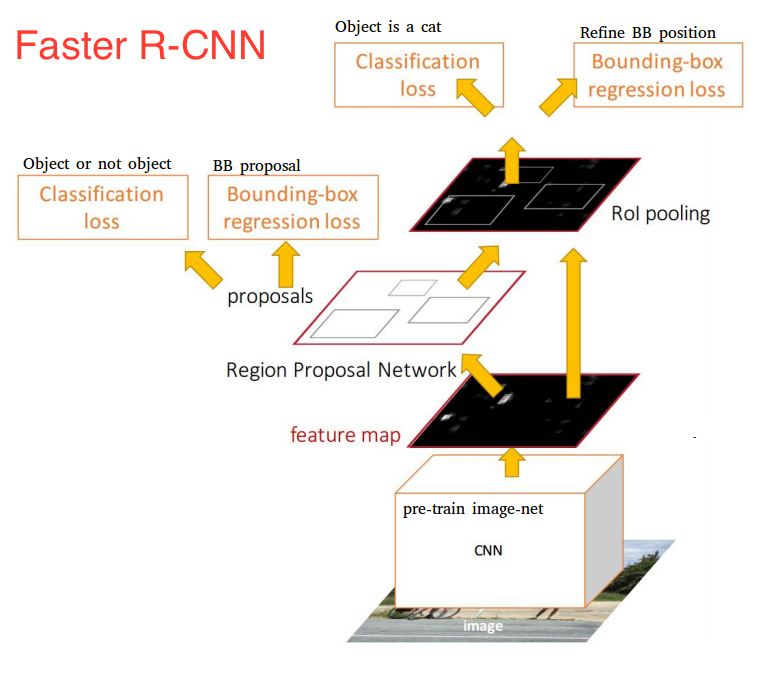
圖片來源:https://heartbeat.fritz.ai/the-5-computer-vision-techniques-that-will-change-how-you-see-the-world-1ee19334354b
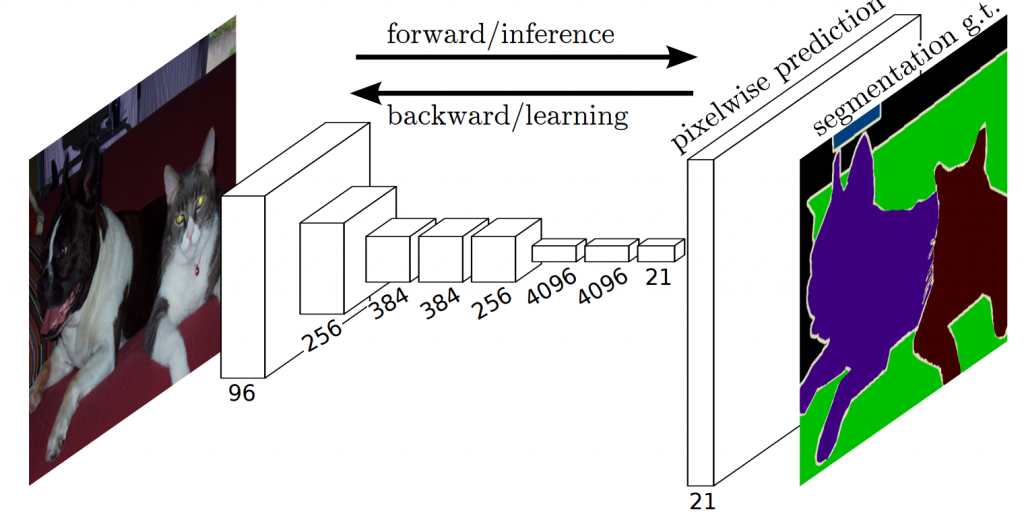
Semantic Segmentation 試圖在語義上理解圖像中每個 pixel 的作用,例如在下圖,除了識別人、道路、汽車、樹木等之外,還必須描繪每個物體的邊界。因此,Semantic Segmentation 與分類不同,需要從模型中進行密集的 pixel-wise 的預測。
圖片來源:https://medium.com/@keremturgutlu/semantic-segmentation-u-net-part-1-d8d6f6005066
Instance Segmentation 將不同類別的 instance 做切割。Instance Segmentation 比分類任務更為複雜,例如景點有多個重疊的物體和不同的背景,不僅要對這些不同的物體進行分類,還要確定它們之間的邊界、差異和關係。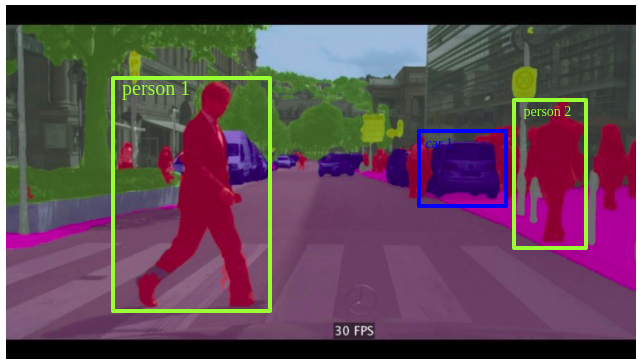
> 圖片來源:https://medium.com/@keremturgutlu/semantic-segmentation-u-net-part-1-d8d6f6005066
Computer Vision 領域深又廣,相關應用還有先前提過的 Generative Models 或用來做視覺化特徵等等。強烈推薦閱讀 [魔法小報] 機器學習路上的強力支援們(網路學習資源推薦) 中列出的 CS231n 課程,你將會學習如何搭建、訓練和校調模型,能夠更深入的進入 Computer Vision 的世界。

